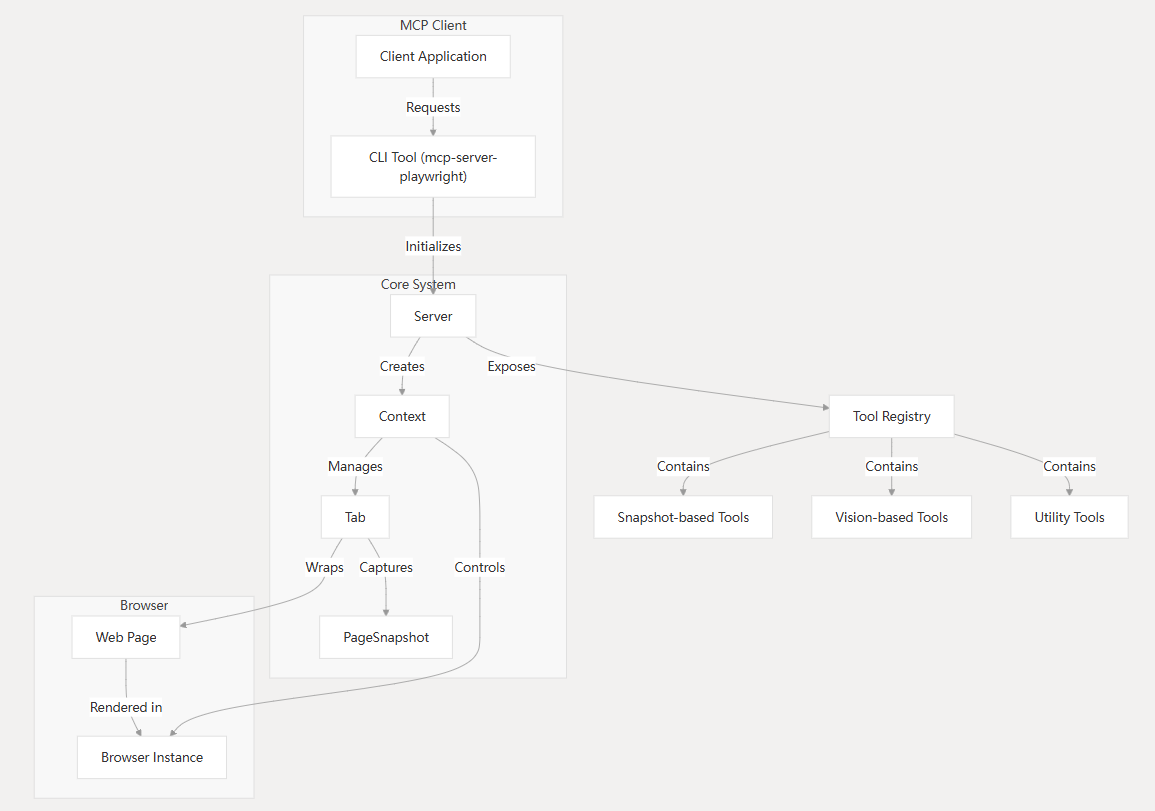
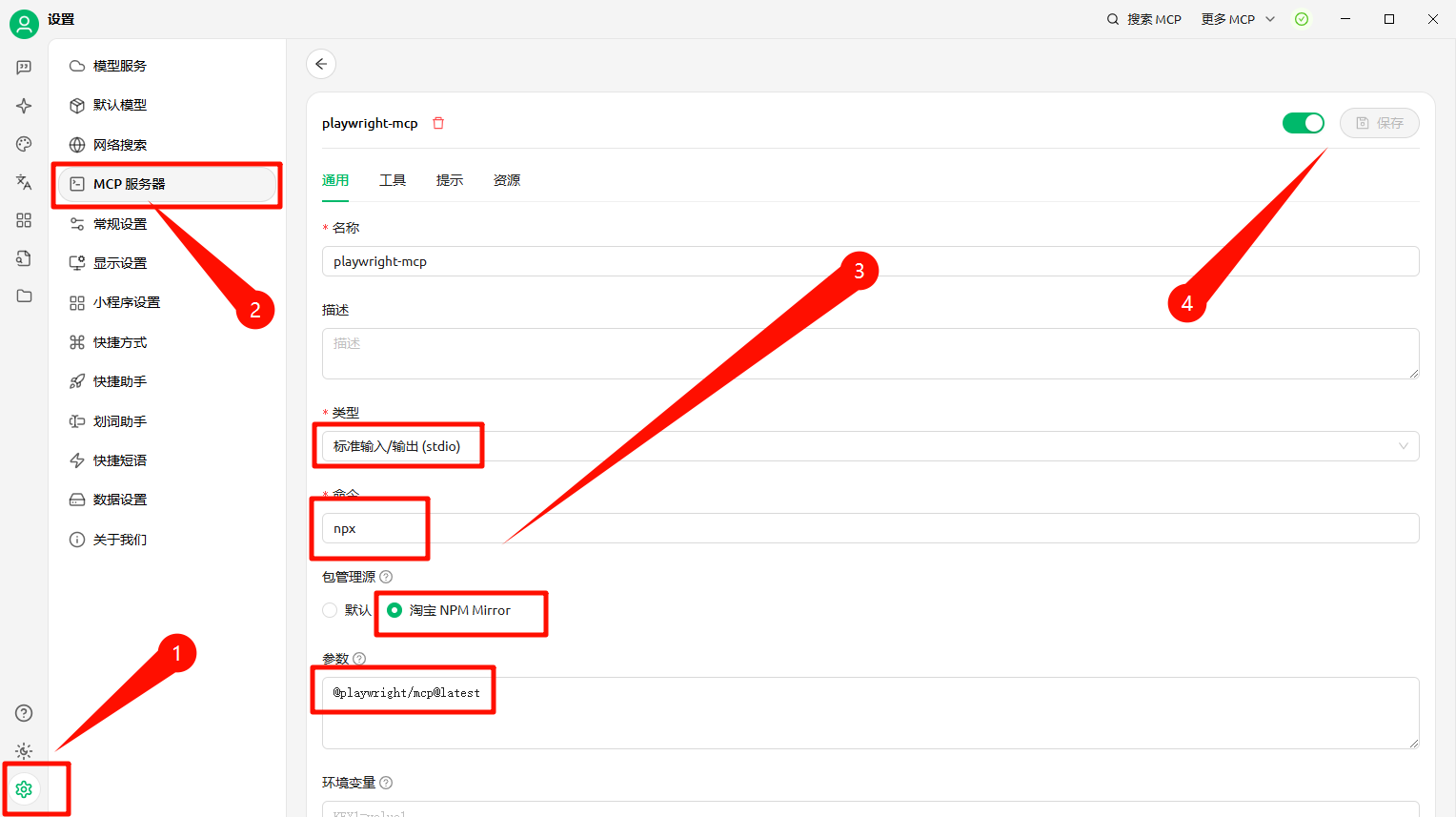
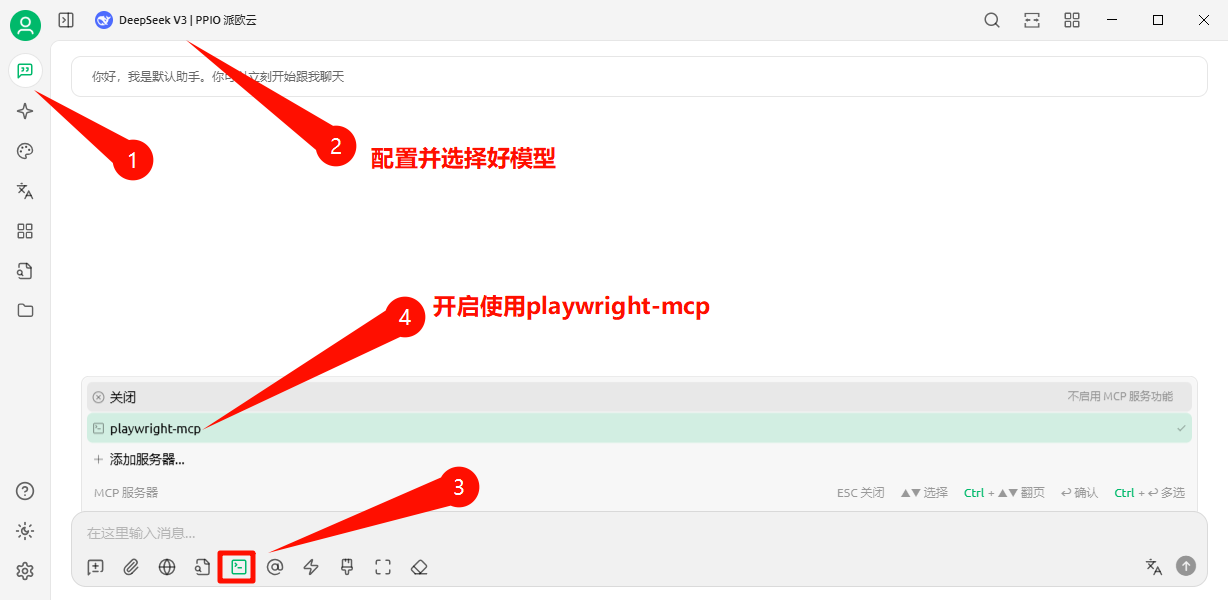
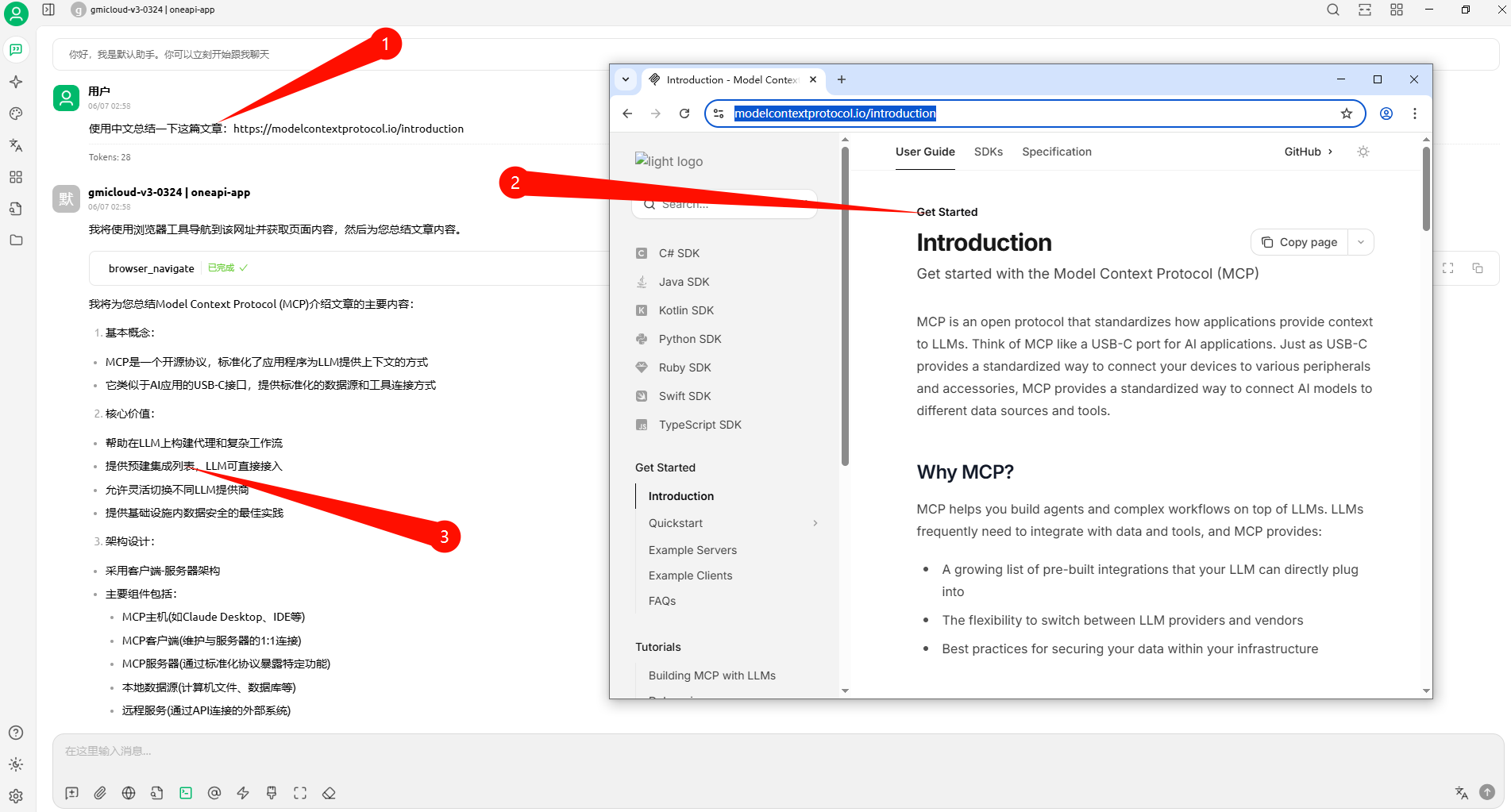
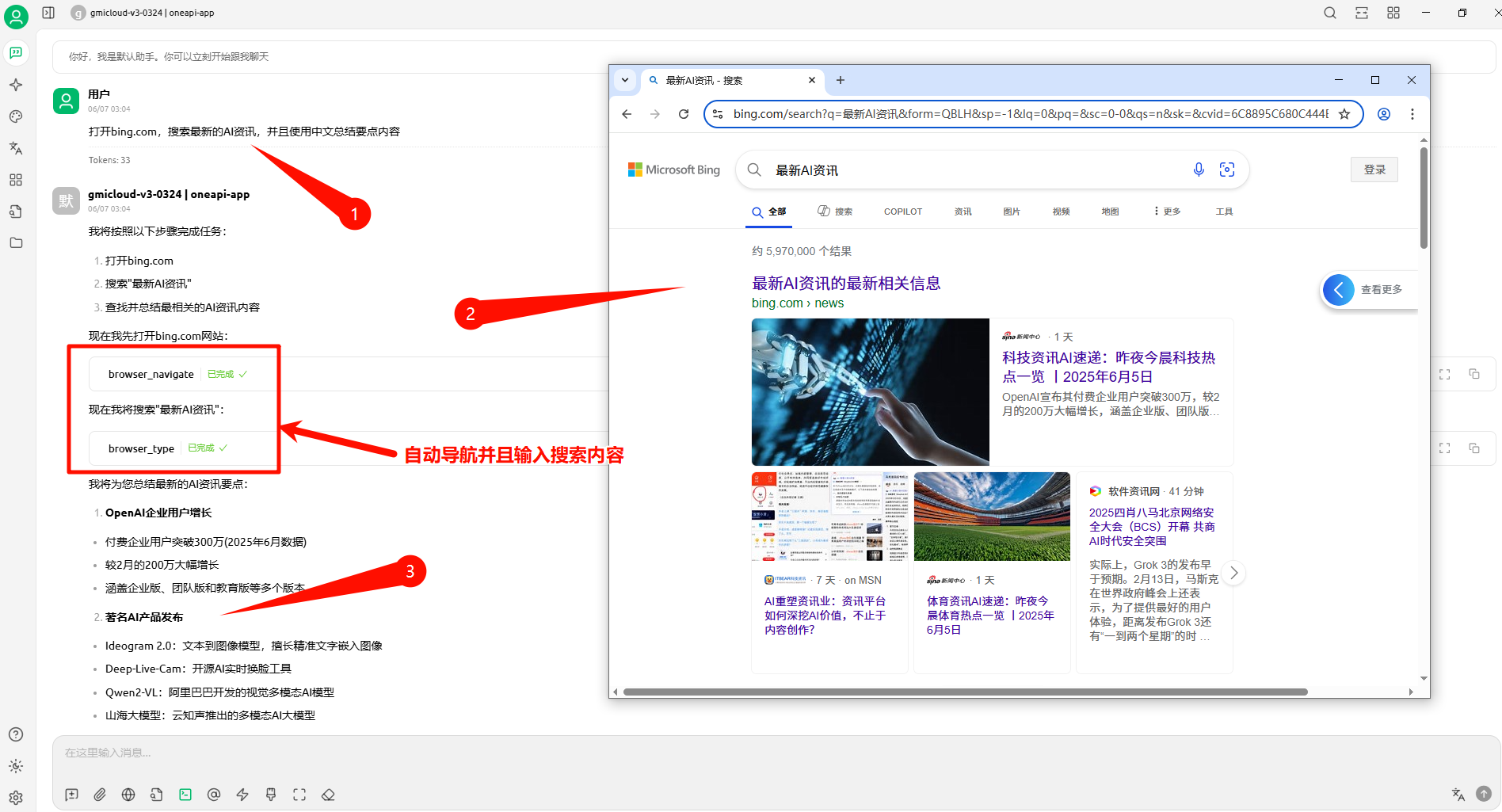
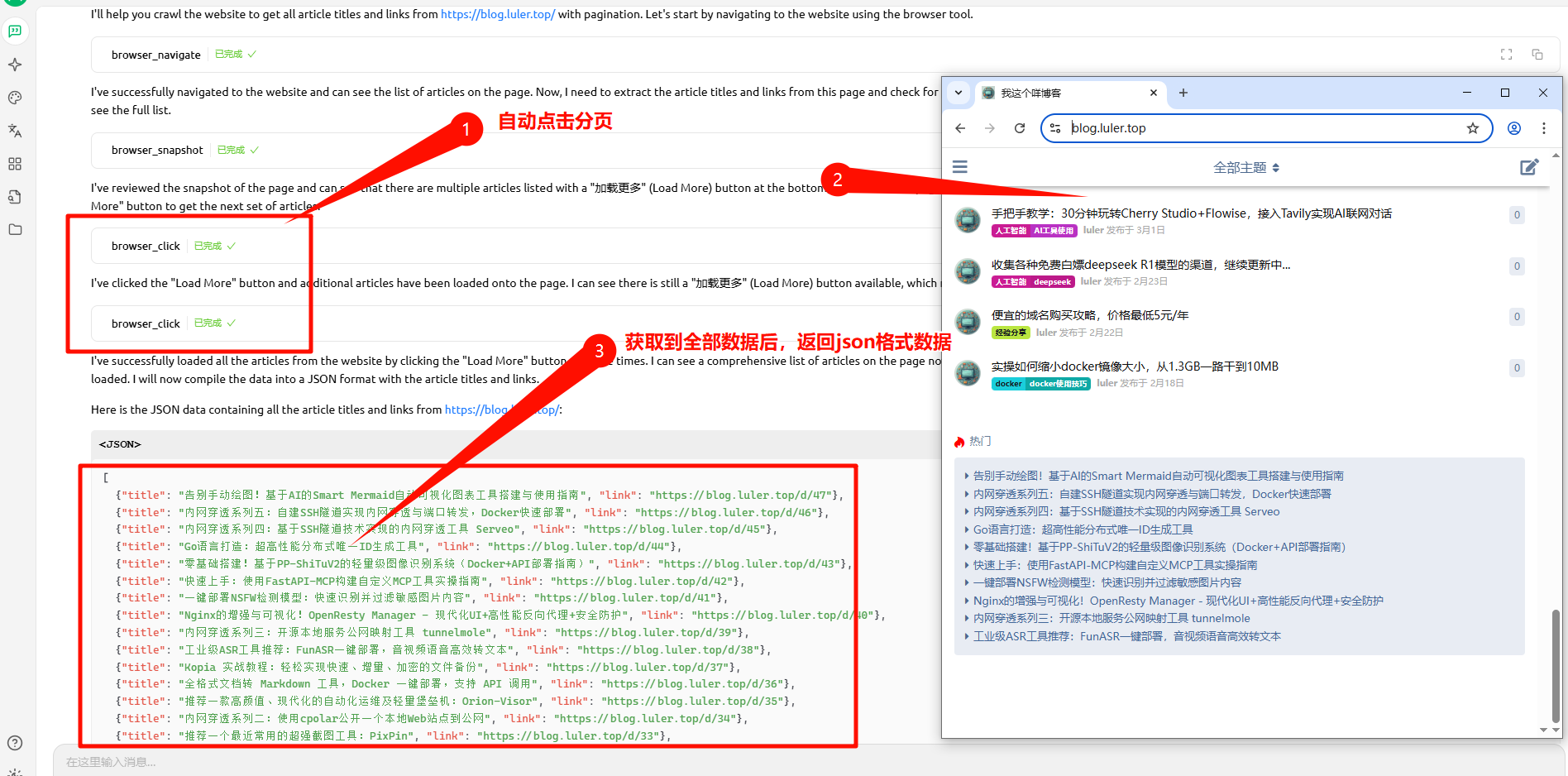
luler 一、简介 Playwright MCP 是一个基于 Playwright 的 MCP 工具,提供浏览器自动化功能 不要求视觉模型支持,普通的文本大语言模型就可以通过结构化数据与网页交互 支持多种浏览器操作,包括截图、点击、拖动、悬停、输入文本等 支持npx直接运行、Docker部署、SSE传输模式,便于集成和扩展 开源项目地址参考:https://github.com/microsoft/playwright-mcp,核心架构参考下图: 二、安装 node 18+、npx环境,MCP服务器配置如下: { "mcpServers": { "playwright": { "command": "npx", "args": [ "@playwright/mcp@latest" ] } } } Docker中运行(只支持headless模式),MCP服务器配置如下: { "mcpServers": { "playwright": { "command": "docker", "args": ["run", "-i", "--rm", "--init", "--pull=always", "mcr.microsoft.com/playwright/mcp"] } } } 独立部署 MCP 服务器,启用SSE传输方式,运行下面命令: npx @playwright/mcp@latest --port 8931 运行成功后,可以使用如下端点接入,配置如下: { "mcpServers": { "playwright": { "url": "http://localhost:8931/sse" } } } 三、使用示例(在Cherry Studio模型对话客户端中使用) 1. 安装Cherry Studio并且配置好Playwright MCP服务器 下载安装Cherry Studio,下载地址:https://www.cherry-ai.com/ 打开MCP服务器,新增并配置Playwright MCP服务器,如下图所示 2. 在Cherry Studio对话框中使用示例 在对话界面选择好对话模型,并且开启要使用的Playwright MCP工具 使用例子一,利用这个工具总结一篇外文网页文章,提示词如下: 使用中文总结一下这篇文章:https://modelcontextprotocol.io/introduction 使用例子二,利用这个工具自动搜索并总结资讯,提示词如下: 打开bing.com,搜索最新的AI资讯,并且使用中文总结要点内容 使用例子三,可以作为自动化信息爬虫使用(非常好用),提示词如下: 爬取所给网站的信息,需要分页获取所有的文章标题title、文章链接link,最后返回json格式数据,这个网站是:https://blog.luler.top/ 四、总结 Playwright MCP比较充分融合AI与浏览器自动化,操作更智能便捷 快速轻量,响应速度快,支持单浏览器实例多客户端共享,资源利用率高 支持多种部署使用方式,特别是可以部署独立部署成SSE服务,实现远程共享 可以完成相对复杂的浏览器自动化任务,比如自动分页信息爬取