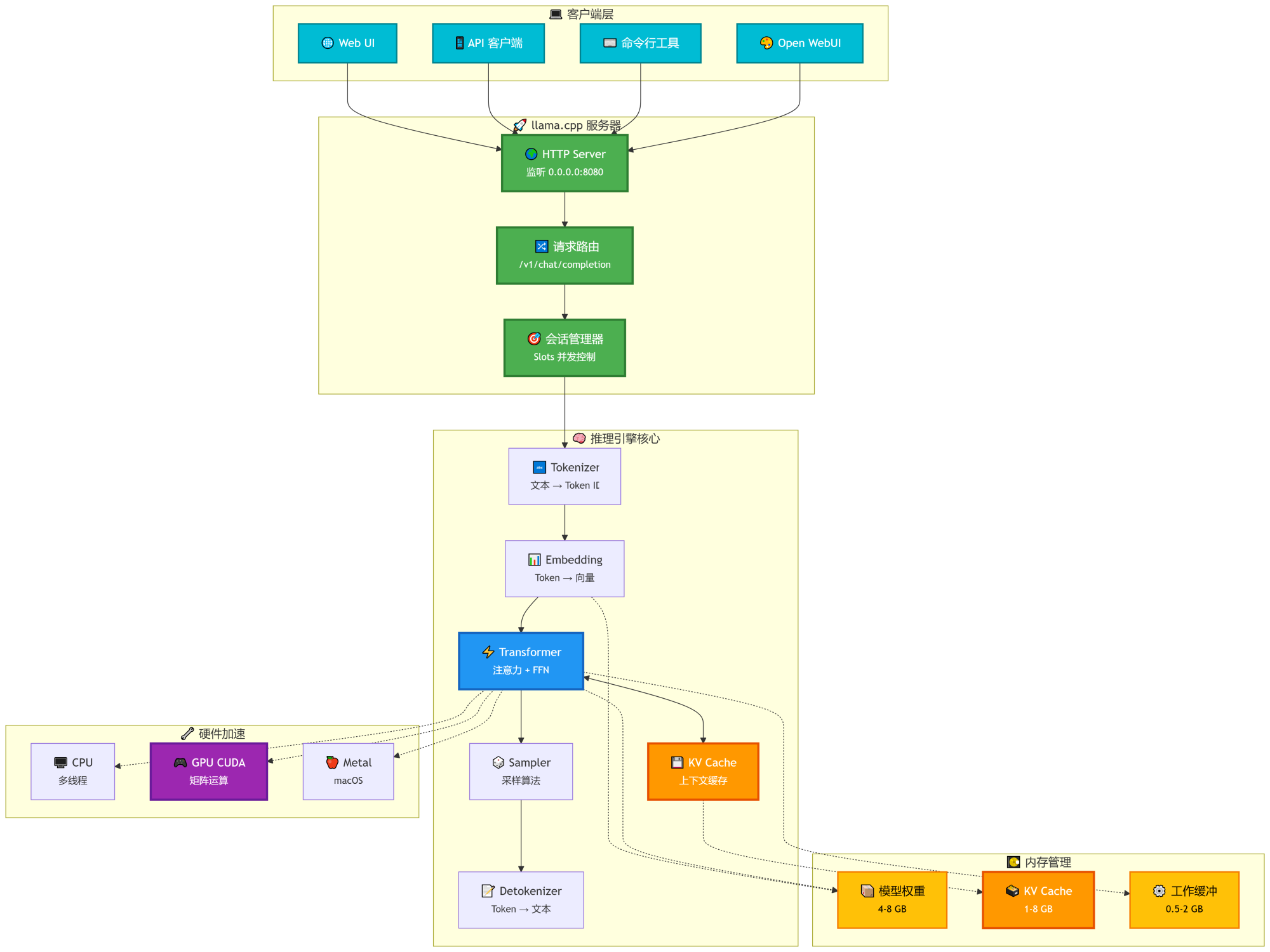
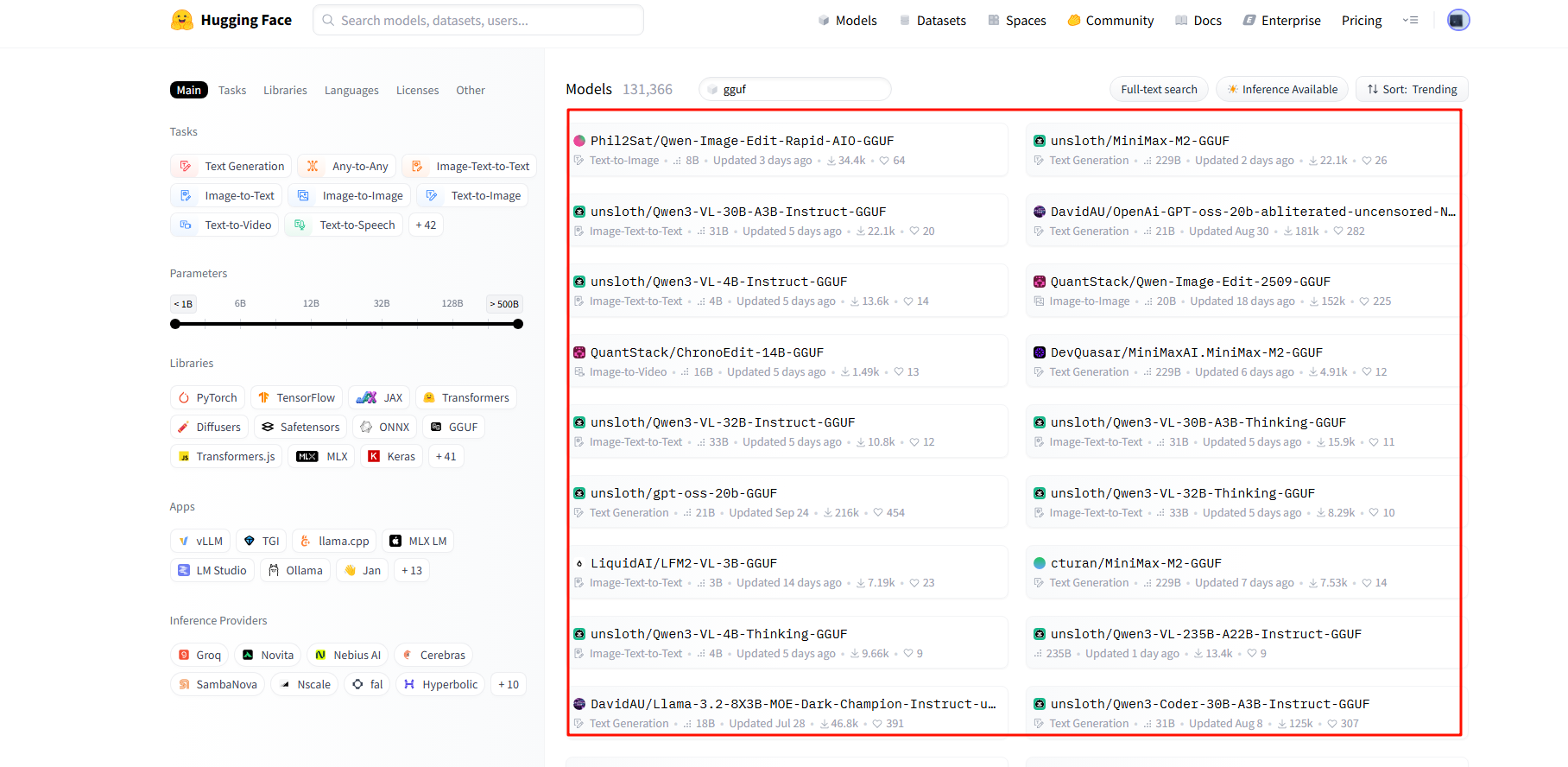
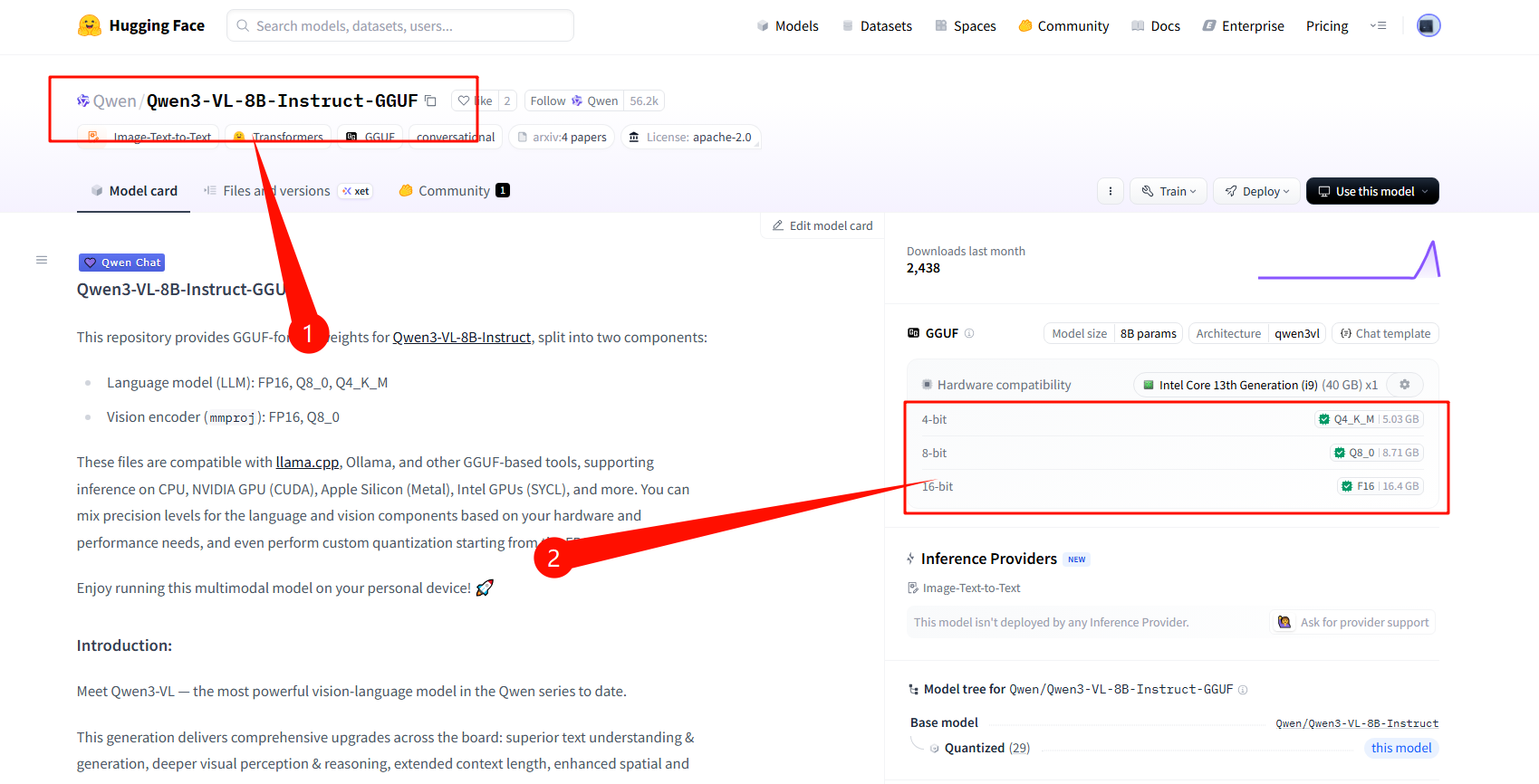
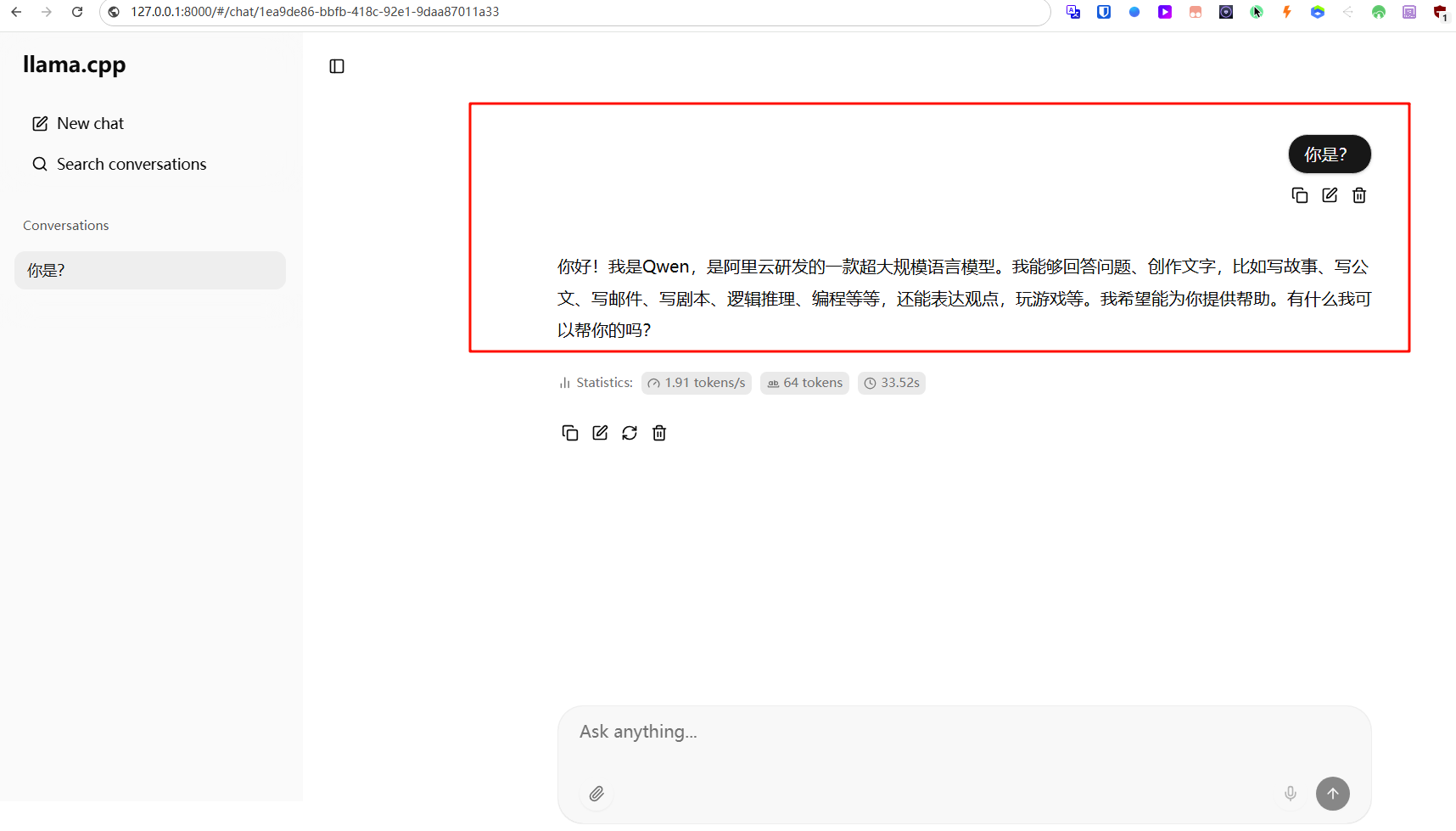
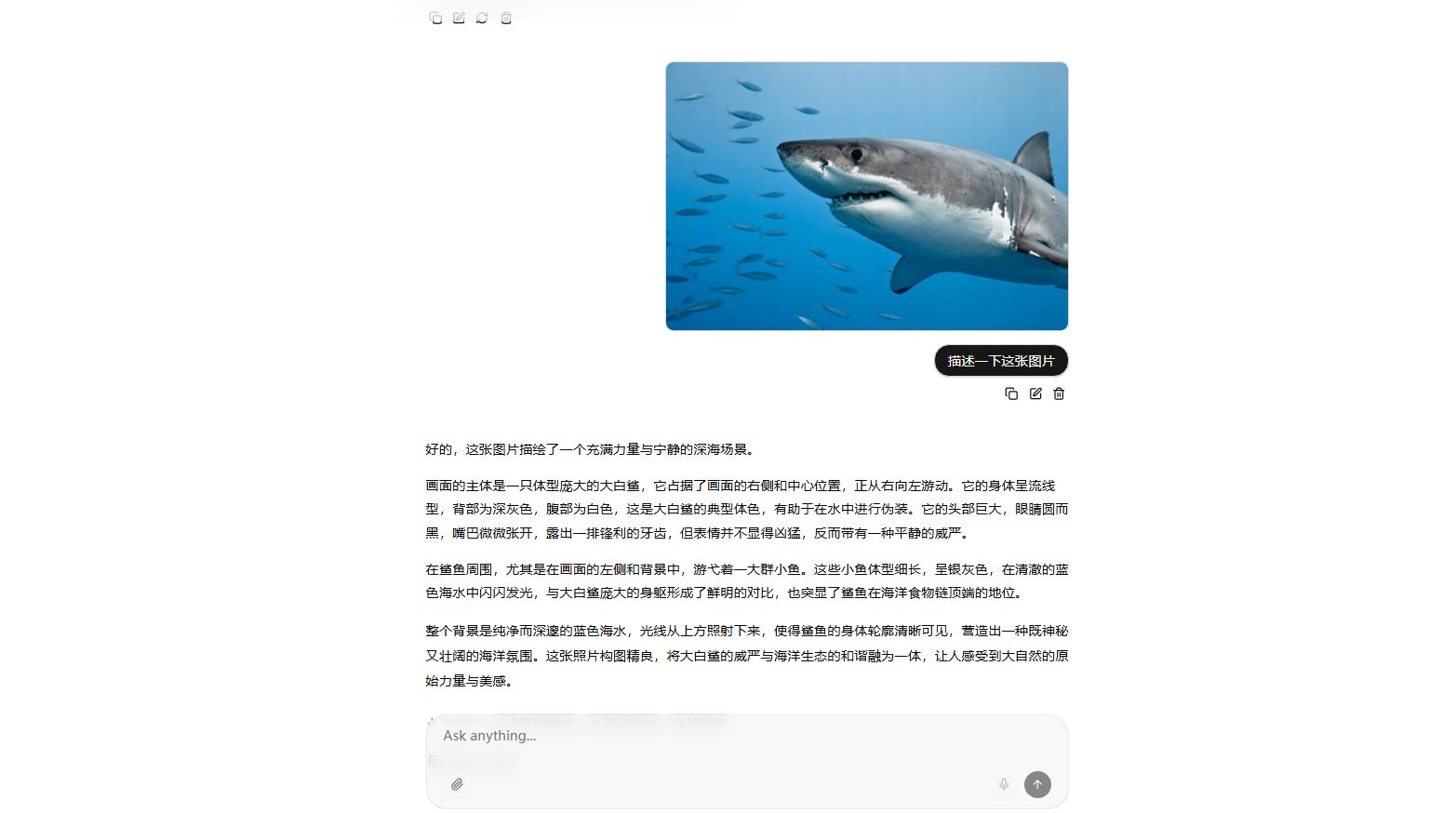
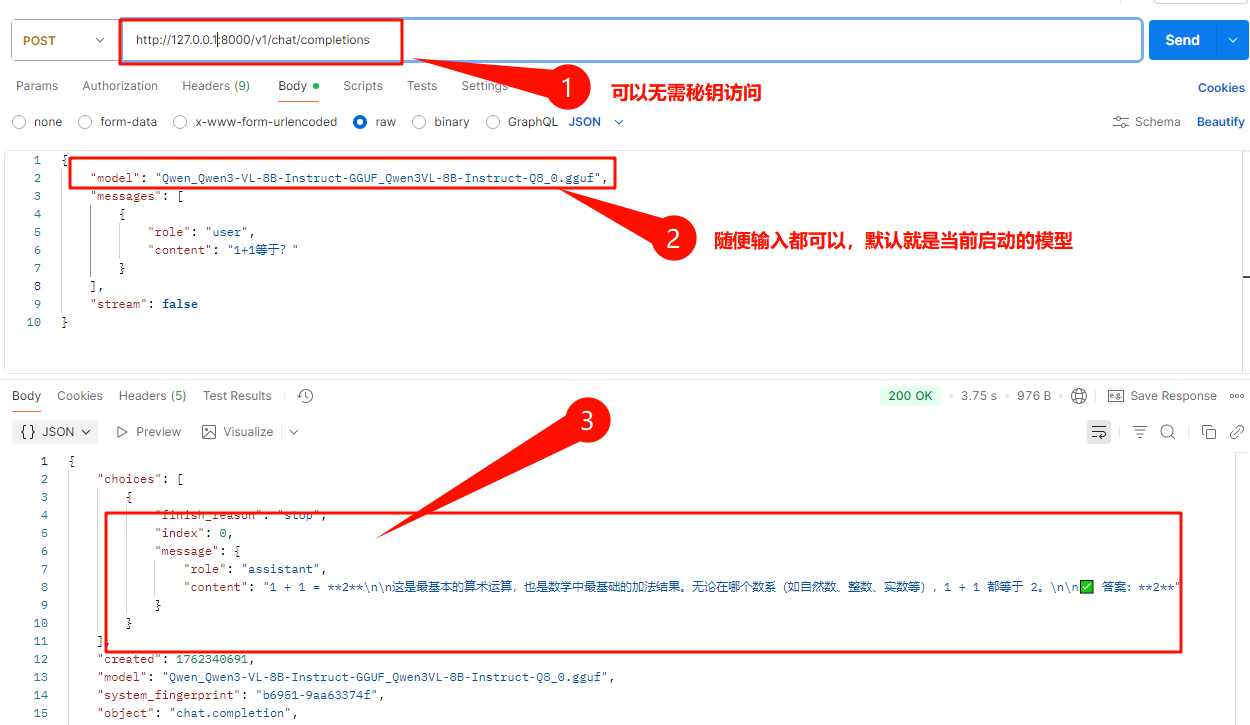
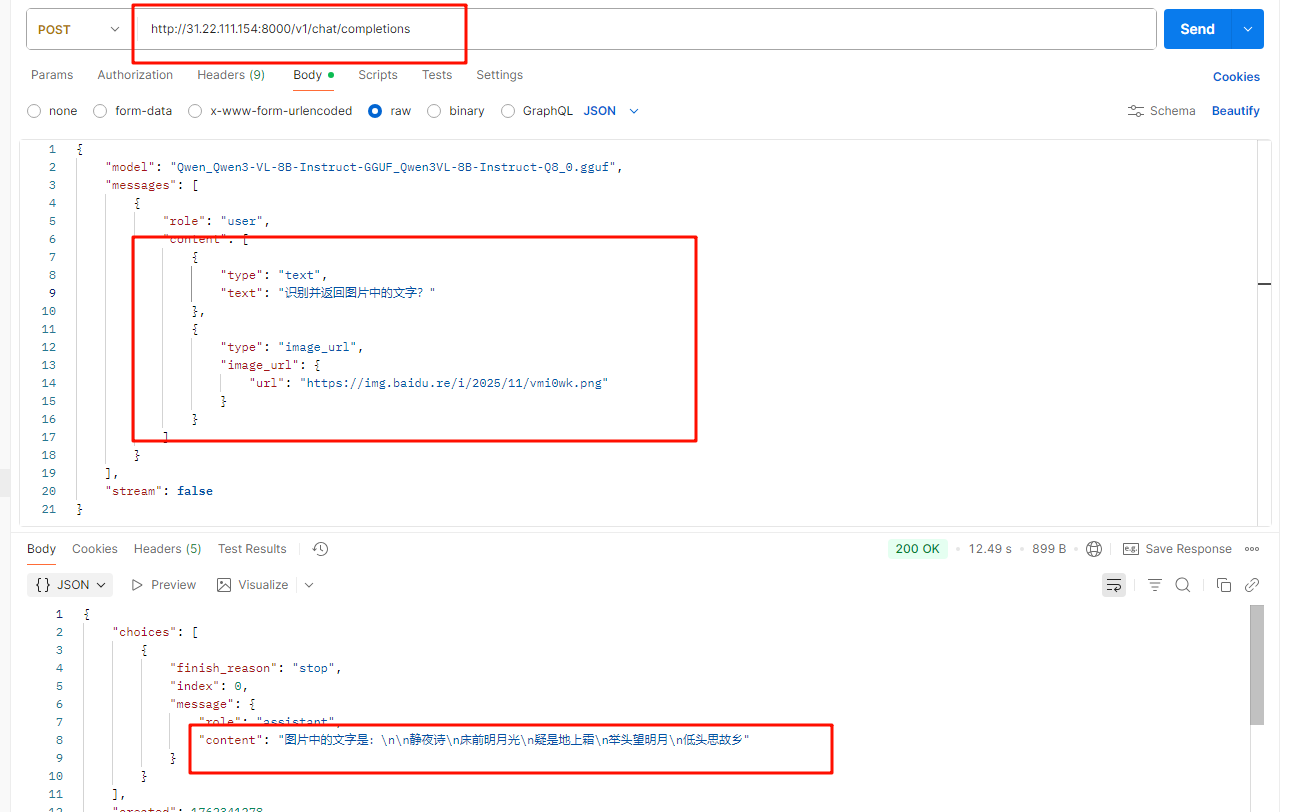
新建docker-compose.yml配置文件,参考下面内容:
CPU运行版本
services:
llama-cpp-server:
image: ghcr.io/ggml-org/llama.cpp:server
ports:
- "8000:8000"
volumes:
- ./cache:/root/.cache
command: >
-hf Qwen/Qwen3-VL-8B-Instruct-GGUF:Q8_0
--jinja
-c 65535
--port "8000"
--host 0.0.0.0
restart: unless-stopped
GPU运行版本
services:
llama-cpp-server:
image: ghcr.io/ggml-org/llama.cpp:server-cuda
ports:
- "8000:8000"
volumes:
- ./cache:/root/.cache
command: >
-hf Qwen/Qwen3-VL-8B-Instruct-GGUF:Q8_0
--jinja
-c 65535
--port "8000"
--host 0.0.0.0
--n-gpu-layers 99
restart: unless-stopped
deploy: #使用GPU主要增加这个配置
resources:
reservations:
devices:
- driver: nvidia
count: all #使用所有GPU,可以指定数量和特定GPU
capabilities: [gpu]
关键参数注解,参考如下
-hf # 从 HuggingFace 自动下载模型
--jinja # 启用聊天格式模板(多轮对话必需)
-c 65535 # 上下文窗口大小(tokens数量,越大占用越多显存)
--port "8000" # 容器内监听端口
--host 0.0.0.0 # 监听所有网络接口(Docker 容器必需)
--n-gpu-layers 99 # GPU 加载层数(99=全部层,0=纯CPU)
更多参数用法参考:https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md